Five labs. One steady rhythm.
Each lab follows the same four-phase practice: Watch → Try → Adjust → Reflect. Same form every week. Different content. Click any week to see what you’ll do.
01
Chapters 1 & 2 · What is AI? + History
Talk to AI old & new
Phone audit + ELIZA vs ChatGPT
Talk to AI old & new
Today you will
Chat with an AI from 1966 and one from today. By the end, you’ll be able to spot the difference between a rule-based system and a learning-based one without being told which is which.
What you’ll do
- Audit your phone: list 5 apps you use that are AI-powered, even if you didn’t know it
- Open ELIZA in one tab and ChatGPT in another
- Send each one the same three prompts (below)
- Compare how each responds to identical input
Did either response feel like it understood you, or just pattern-matched?
Where did each one break down, repeat itself, or feel hollow?
If you didn’t know which was from 1966, could you tell?
02
Chapters 3 & 4 · Data + ML Fundamentals
Train your own AI
Build a classifier in 10 minutes — twice
Train your own AI
Today you will
Train your own image classifier from scratch using your laptop’s webcam. By the end, you’ll have a working AI you built yourself — and you’ll have felt why bad data makes bad AI.
What you’ll do
- Pick two simple things to tell apart (e.g., pen vs. phone, thumbs-up vs. peace sign, banana vs. apple)
- Round 1 — train it badly: capture only 10 photos of each, all from the same angle, same lighting
- Test it. Watch it fail. Note where and why
- Round 2 — train it well: capture 30+ photos of each, vary the angle, distance, and lighting
- Test again. Compare the confidence scores side by side
- Round 3 (optional): add a third category, or train on something of your choice
What kinds of photos did Round 1 fail on? What did it confidently get wrong?
What changed between Round 1 and Round 2 — was it the model, or the data?
Where in your real life have you seen AI fail in a similar way?
When you train an AI, who does it work for?
-
Who’s in your training data?
- If you trained on only yourself, who is it accurate for?
- Would a friend with a different skin tone or hand size get the same result?
A model only knows what it was shown. Limited data = limited audience.
-
What environment was the data collected in?
- Will it work outside this exact room?
- What changes if the lighting, background, or distance shifts?
Models silently fail when conditions don’t match training.
-
What’s missing from your training data?
- What did you not show the model?
- What happens when the model sees something it’s never seen before?
AI can’t say “I don’t know” — it always picks something. That confident wrong answer is the dangerous one.
-
Whose voices, faces, or experiences are over-represented?
- Who built the AI most people use today?
- If they share a similar background, what becomes “normal” — and what gets treated as the exception?
Training data reflects who built it. That’s why AI tends to work best for some groups and worst for others.
-
What’s the cost of being wrong?
- Is this AI used for fun, or for decisions that affect someone’s life?
- A misclassified gesture in a game vs. a misclassified face in airport security — same error, different consequences. What’s the difference?
The bigger the decision, the more careful the data needs to be.
-
Did the people in your training data agree to be there?
- Where did the data come from?
- Did the people in it know — and would they have said yes?
Consent in AI training is rare. That’s a fairness issue most people don’t think about.
03
Chapters 5 & 6 · Deep Learning + NLP/CV
Look inside the AI
CNN Explainer + Tokenizer
Look inside the AI
Today you will
Open up a real neural network and watch it process an image, layer by layer. Then see exactly how AI breaks language into numbers — including what it does to your own name.
First — what is CNN Explainer actually showing you?
A neural network is just lots of small “pattern detectors” stacked in layers. Each layer looks at a slightly bigger pattern than the one before it. CNN Explainer lets you see those layers light up while it tries to figure out what your image is.
An analogy: imagine spotting a friend across a crowded room. Your eyes don’t see “Sarah” instantly. First you notice a human shape. Then a hair color. Then familiar facial features. Then — oh, that’s Sarah. A neural network does the same thing in stages: pixels → edges → shapes → objects. CNN Explainer just makes those stages visible.
Part A — CNN Explainer (vision)
- Open CNN Explainer. It loads with 10 sample images already at the top — click any one of them to use it
- You’ll see colorful blocks (the “layers”) running left to right. The image enters on the left; the network’s guess comes out on the right
- Click on any small colored square (a “neuron”) in the first layer. See what part of the image it’s reacting to (usually edges or color blobs)
- Now click a neuron in a deeper layer (further to the right). Notice how the patterns are bigger and more complex
- Pick one hidden layer and stay there for 3 minutes. Look hard. What is it actually responding to?
- Want to upload your own image? CNN Explainer was trained on 10 specific things: pizza, espresso, sport car, school bus, red panda, koala, ladybug, lifeboat, bell pepper, and orange. Use a clear photo of one of those for best results. Need a sample? Try one from the Wikipedia Pizza article — right-click and save any photo there.
Part B — Tokenizer (language)
- Open Tiktokenizer. Try the prompts below in the input box
- Watch how each piece of text breaks into tokens (the colored boxes)
- Note the token count for each — this is what AI actually sees and what you’d be charged for
In CNN Explainer, what was the difference between an early layer and a deep layer?
Which of your tokenizer inputs had surprisingly many tokens? Why might that be?
If AI was trained mostly on English text, how might that affect users like you?
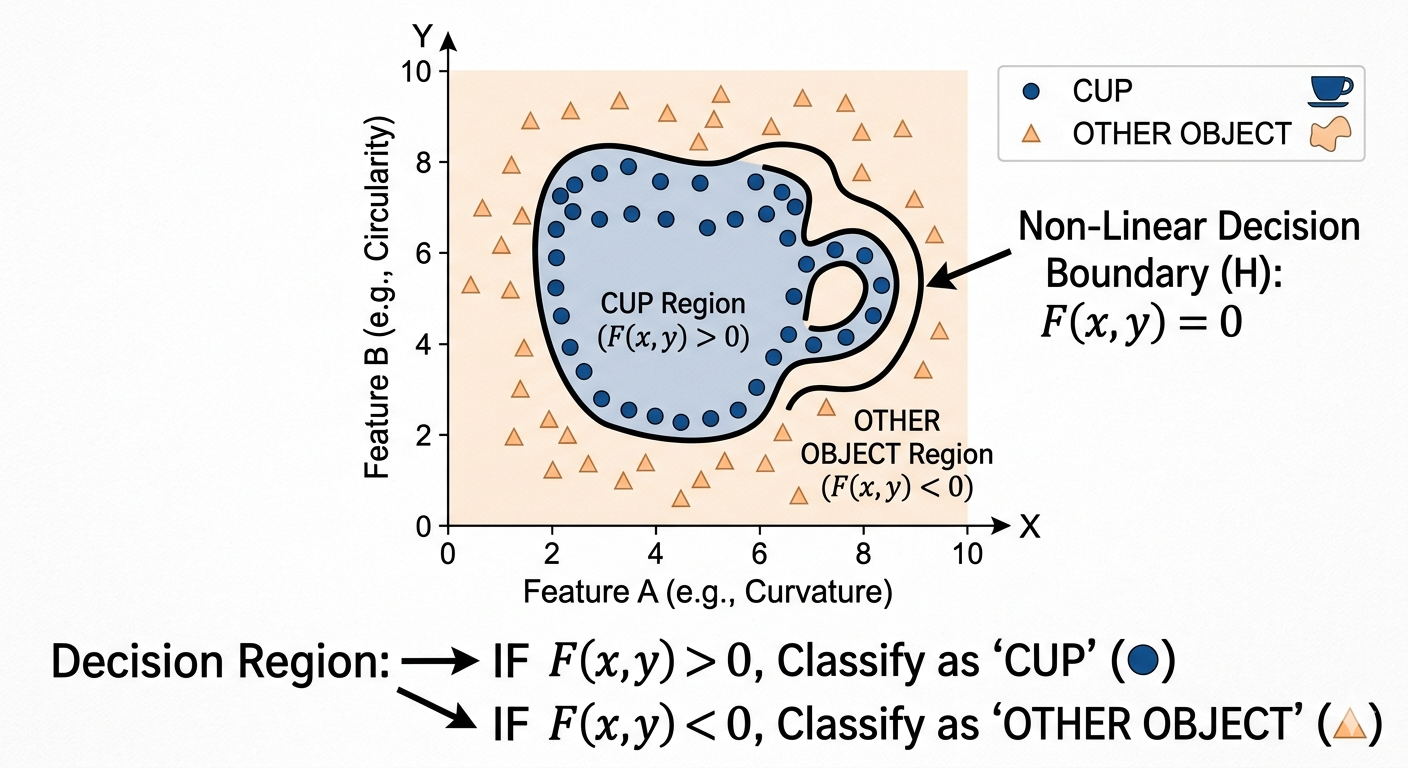
If this picture clicks for you — the idea that the network is just learning where to draw the line between “cup” and “not cup” in a space of features — you’ve got the core intuition behind every CNN (and most classifiers). The rest is just adding more dimensions and more layers.
Optional deep dive · 8 min read
How AI actually works — a visual walkthrough
From input text to generated answer, with diagrams
The pipeline at a glance
Every AI response, no matter how complex it sounds, goes through the same five-step pipeline. The “intelligence” lives in steps 3 and 4. Everything else is repetition.
STEP 01Tokenize
The model doesn’t see words — it sees tokens (chunks). The word “capital” might be one token; “unbelievable” might split into un + believ + able. Roughly 1 token ≈ 0.75 words in English. This is exactly what you’ll see in Tiktokenizer in Part B — tokens are the unit of pricing, the unit of context limits, and the unit the model actually reasons over.
STEP 02Embed
Each token gets converted into a long list of numbers — a vector, often with 1,000 or more dimensions. This is where meaning lives. Words with similar meanings get similar vectors. This is the foundation of semantic search:
Why this matters: when someone searches “kitten,” the system converts that query into a vector and finds the nearest neighbors in this space — cat, dog, lion — even though “kitten” never appears in the source text. That’s why “car broke down” can match “vehicle malfunction.” Keyword search can’t do that.
STEP 03Process (attention)
The model looks at all tokens at once and decides which ones matter for understanding each word. In “The bank by the river,” attention figures out that river is what makes bank mean shoreline, not financial:
This attention step happens across dozens of stacked layers, each refining understanding further. By the top layer, the model has a rich representation of what’s being asked.
STEP 04Predict next token
The model outputs a probability score for every possible token in its vocabulary (~100,000+ options). It picks the most likely one, or samples from the top few for variety:
STEP 05Loop until done
Here’s the part most people miss: the model only predicts one token at a time. It picks “mat,” appends it to the input, and runs the entire pipeline again to predict the next token. That’s why responses stream word by word — each one is a fresh trip through the pipeline.
What this means in practice
- No memory between conversations — unless explicitly given (system prompts, retrieval). Each request starts fresh.
- Context window = working memory. The model can only “see” what’s in the current prompt. Long documents need chunking.
- Hallucinations come from step 4 — the model picks the most likely next token, not the most true one. Grounding it in trusted source material is how you get reliability.
- Semantic search (the embedding step) is why AI can match meaning, not just keywords — the highest-leverage piece for content discovery and archive search.
04
Chapters 7 & 8 · Generative AI + Applications
Make AI lie. Catch it.
Prompt lab + Hallucination hunt
Make AI lie. Catch it.
Today you will
Run the same task through three different prompt styles and see how the output changes. Then deliberately make the AI hallucinate a fact, and prove the lie. By the end, you’ll know how to get more out of AI — and how to never trust it blindly.
Part A — Three prompt styles, same task
Pick a task. Send it to ChatGPT three different ways. Compare the outputs.
Part B — Hallucination hunt
Pick one of these prompts. Send it to ChatGPT. The AI will likely invent something. Your job is to verify it with a real source (Google, Wikipedia, or a real database).
Which of the three prompt styles gave you the best output? Why?
How confident did the AI sound when it was lying? Could you have caught it without checking?
Where in your life would an AI hallucination cause real problems?
05
Chapters 9 & 10 · Ethics + Strategy/Careers
Audit AI bias. Plan your path.
Side-by-side bias audit + personal AI roadmap
Audit AI bias. Plan your path.
Today you will
Run identical prompts through two of the world’s most popular AI systems and document what you find. Then build a personalized 6-month AI learning roadmap based on your career goals.
Part A — Bias audit (30 min)
Open ChatGPT in one tab and Gemini in another. Send each one the prompts below. Document the differences.
Part B — Your AI roadmap (30 min)
Use the prompt below in either ChatGPT or Gemini. Customize it with your real major, year, and goals. Save the response.
For each bias prompt, did the two AIs give similar or different answers? What did they assume by default?
Were there any prompts where one AI was clearly more biased than the other?
Looking at your roadmap: which suggestions feel realistic for you, and which don’t fit your reality? What does that gap tell you?